HookMesh vs LLMWise
Side-by-side comparison to help you choose the right tool.
Enhance your SaaS with reliable webhook delivery, automatic retries, and a self-service portal for seamless integration.
Last updated: February 28, 2026
Access all top AI models through one API with smart routing and pay only for what you use.
Last updated: February 28, 2026
Visual Comparison
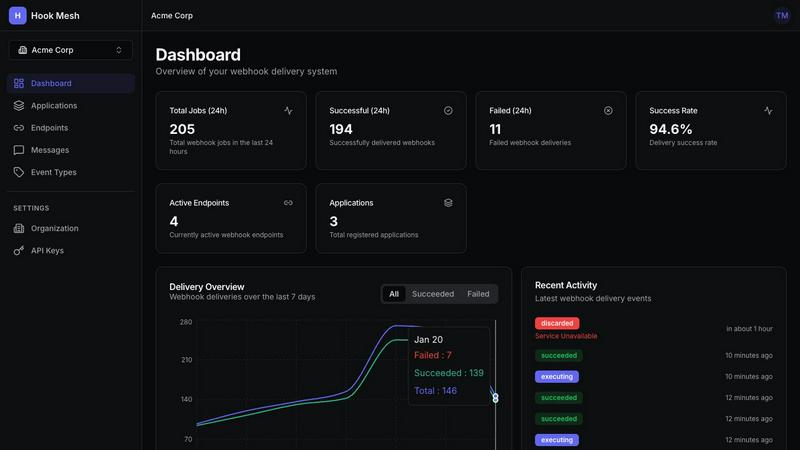
HookMesh
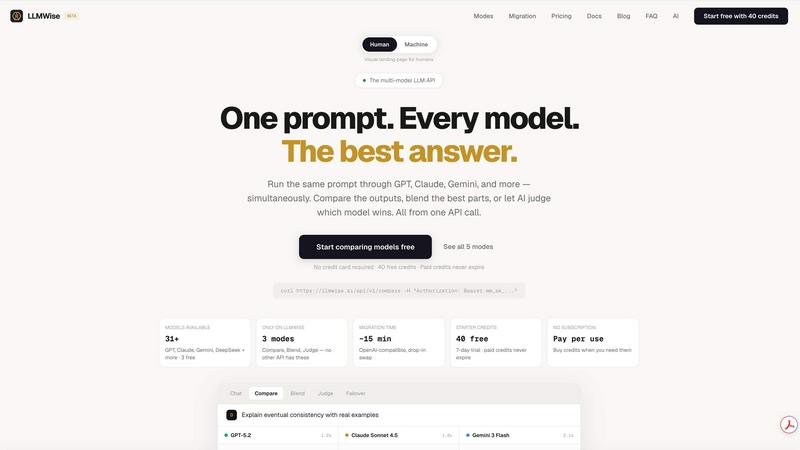
LLMWise
Feature Comparison
HookMesh
Reliable Delivery
HookMesh guarantees that webhooks are never lost, thanks to its sophisticated delivery mechanisms. With automatic retries and exponential backoff strategies, the platform ensures that messages are retried for up to 48 hours if initial attempts fail. This feature is crucial for maintaining data integrity and ensuring that no critical event goes unreported.
Customer Portal
The self-service customer portal is a standout feature of HookMesh, offering an embeddable UI for endpoint management. Customers can easily add or modify their webhook endpoints, view comprehensive delivery logs, and replay failed webhooks with just one click. This transparency and control significantly enhance the user experience, reducing the need for support interventions.
Circuit Breaker
The circuit breaker feature automatically disables any endpoints that are consistently failing, preventing a single slow or down endpoint from impacting the entire webhook queue. Once the issue is resolved, HookMesh allows for seamless re-enablement, ensuring that your webhook delivery remains efficient and effective.
Developer Experience
HookMesh is designed with developers in mind, offering a REST API and official SDKs for JavaScript, Python, and Go. The platform's easy integration process requires only a few lines of code to get started. This streamlined developer experience allows teams to implement webhook functionality quickly and efficiently.
LLMWise
Intelligent Model Routing
This is the foundational, must-have feature. You send a single prompt to the LLMWise API, and its smart routing engine automatically selects the optimal large language model for that specific task. It intelligently matches prompts to model strengths, sending coding queries to GPT, creative briefs to Claude, and translation requests to Gemini. This eliminates the guesswork and manual model selection, ensuring you consistently get the highest quality output for every request without any extra effort.
Compare, Blend, and Judge Modes
LLMWise provides essential orchestration modes that are critical for production-grade AI applications. Compare mode runs a single prompt across multiple models side-by-side in one request, allowing you to instantly benchmark speed, cost, and output quality. Blend mode takes this further by synthesizing the best parts of each model's response into one superior, consolidated answer. Judge mode enables models to evaluate and critique each other's outputs, providing an automated layer of quality assurance and validation.
Resilient Circuit-Breaker Failover
This feature is non-negotiable for any serious application. LLMWise includes a built-in circuit-breaker system that provides automatic failover to backup models if a primary provider experiences downtime or high latency. This ensures your application remains operational and resilient, never breaking due to external API outages. It is a critical component for maintaining uptime and delivering a reliable experience to your end-users without manual intervention.
Test, Benchmark, and Optimize Suite
You must have the tools to optimize performance and cost. LLMWise offers a comprehensive suite for testing and optimization, including benchmark suites, batch testing capabilities, and configurable optimization policies. You can set policies to prioritize speed, cost, or reliability for different types of requests. Automated regression checks ensure new model versions or prompts do not degrade your application's output quality, making it an indispensable tool for continuous improvement.
Use Cases
HookMesh
E-Commerce Transactions
In the e-commerce sector, businesses rely heavily on webhooks to process transactions and order updates. HookMesh ensures that critical events like order completions and payment confirmations are delivered reliably, enhancing customer satisfaction and operational efficiency.
SaaS Integrations
For SaaS products that integrate with multiple services, HookMesh provides a robust solution for managing webhooks. By simplifying endpoint management and ensuring reliable delivery, HookMesh allows SaaS providers to focus on delivering value rather than troubleshooting webhook issues.
Real-Time Notifications
Businesses that require real-time notifications, such as alerts for system status changes or performance metrics, benefit from HookMesh's automatic retry and logging features. This guarantees that all stakeholders receive timely updates, fostering proactive decision-making.
API Event Management
HookMesh is ideal for managing events in applications that utilize APIs. With its reliable delivery and self-service capabilities, developers can effectively orchestrate event-driven architectures without the overhead of maintaining complex webhook systems.
LLMWise
Development and Prototyping
Developers can rapidly prototype and build AI features using the 30 permanently free models available at zero cost. This allows teams to test ideas, validate prompts, and ship initial versions of their application without any financial commitment. The compare mode is essential for debugging and determining which model handles specific edge cases or instructions most effectively during the development phase.
Production Application Orchestration
For applications in production, LLMWise is a necessity for managing AI workloads reliably and cost-effectively. The smart routing ensures every user query is handled by the best-suited model, while the failover system guarantees uptime. Companies can implement optimization policies to balance response speed and cost across millions of requests, ensuring a scalable and efficient AI backend through a single, simple API integration.
AI Output Quality Enhancement
Teams that require the highest possible quality output must use the Blend and Judge modes. This is critical for generating marketing copy, legal document analysis, complex research summaries, or competitive intelligence reports. By leveraging multiple top-tier models and synthesizing their strengths, you can produce results that surpass the capability of any single provider, turning AI from a tool into a competitive advantage.
Cost Optimization and Vendor Management
LLMWise is essential for finance-conscious teams tired of subscription sprawl. The platform allows you to bring your own API keys (BYOK) and pay provider prices directly, eliminating markups. Alternatively, you can use a unified credit system. This approach, combined with the ability to compare model costs per request and utilize free models for fallback, provides unprecedented visibility and control over AI expenditure, making it a mandatory financial management tool.
Overview
About HookMesh
HookMesh is a cutting-edge platform tailored to revolutionize webhook delivery for modern Software as a Service (SaaS) products. As businesses increasingly rely on webhooks for real-time communication and data exchange, the challenges of managing these hooks in-house can become overwhelming. HookMesh mitigates these complexities, providing an all-in-one solution that includes automatic retries, circuit breakers, and advanced debugging tools. Designed for developers and product teams, HookMesh allows organizations to concentrate on enhancing their core offerings rather than getting tangled up in the technical intricacies of webhook management. With a battle-tested infrastructure that guarantees reliable delivery, businesses can ensure that critical events reach their intended destinations without fail. Additionally, HookMesh features a self-service portal that empowers customers to manage their endpoints, view logs, and effortlessly replay failed webhooks with a single click. This innovative approach not only streamlines webhook handling but also elevates the overall customer experience, making HookMesh an essential tool for any organization looking to optimize their webhook strategy.
About LLMWise
LLMWise is the essential, unified API platform for developers and businesses that demand the best AI performance for every task without the operational nightmare. It solves the critical problem of AI provider fragmentation by giving you a single, powerful endpoint to access over 62 models from 20+ leading providers, including OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek. The core value proposition is absolute necessity: stop juggling multiple subscriptions, managing separate API keys, and guessing which model to use. LLMWise introduces intelligent orchestration, where smart routing automatically matches each prompt to the optimal model based on its specialty—code to GPT, creative writing to Claude, translation to Gemini. Beyond simple access, it provides must-have tools for comparison, blending outputs for superior quality, and ensuring resilience with automatic failover. Built for developers who prioritize performance, cost-efficiency, and reliability, LLMWise eliminates complexity and locks you into a pay-as-you-go model with no subscriptions, ensuring you only pay for what you use while maintaining complete control.
Frequently Asked Questions
HookMesh FAQ
What kind of events can I send using HookMesh?
HookMesh supports any JSON payload, allowing you to send a wide range of events including transaction updates, notifications, and API callbacks. This flexibility makes it suitable for various applications.
How does HookMesh ensure reliable webhook delivery?
HookMesh employs automatic retries, exponential backoff, and circuit breaker mechanisms to ensure that webhooks are reliably delivered. This comprehensive approach minimizes the risk of lost messages and enhances overall performance.
Is there a limit on the number of webhooks I can send?
Yes, HookMesh offers different pricing tiers with varying limits on the number of webhooks. The free tier includes up to 5,000 webhooks per month, making it accessible for small projects and startups.
How can my customers manage their webhook endpoints?
Customers can use the embedded self-service portal provided by HookMesh to manage their webhook endpoints. This portal enables them to add, modify, and view logs for their endpoints, as well as replay any failed webhooks instantly.
LLMWise FAQ
How does the pricing work?
LLMWise operates on a transparent, pay-as-you-go credit system with no monthly subscriptions. You start with 20 free trial credits that never expire. After that, you only pay for what you use. Crucially, you have two options: you can use LLMWise credits, or you can Bring Your Own Keys (BYOK) from providers like OpenAI and Anthropic and pay their standard rates directly through LLMWise's dashboard. Over 30 models are also available at a permanent cost of 0 credits for testing and fallback.
What are the free models?
LLMWise provides access to over 30 models that cost 0 credits to use, permanently. This includes models from Google (Gemma 3 series), Meta (Llama series), Arcee AI, Mistral, and others. These are essential for prototyping, serving as a cost-free fallback path during traffic spikes, and for benchmarking against paid models to make informed routing decisions. The availability of these free models is automatically synced from the providers' own catalogs.
How does the smart routing work?
The smart routing feature automatically analyzes your prompt and directs it to the model best suited for the task. This routing is based on proven model specialties—for instance, code generation and complex reasoning are routed to models like GPT-4o or GPT-5.2, while creative writing and nuanced dialogue are sent to Claude Sonnet or Opus. This ensures you consistently get optimal performance without needing to be an expert on every model's specific capabilities.
Is there a risk of vendor lock-in?
No, avoiding vendor lock-in is a core principle of LLMWise. By using the platform, you are actually future-proofing your application against lock-in to any single AI provider. Your integration is with the LLMWise API. If a new, superior model is released from any provider, you can immediately access it through the same endpoint. Furthermore, the BYOK option means you maintain direct relationships with providers, and you can easily compare all alternatives side-by-side.
Alternatives
HookMesh Alternatives
HookMesh is a cutting-edge platform designed for reliable webhook delivery, catering primarily to SaaS businesses. It simplifies the complexities of webhook management, allowing developers and product teams to focus on their core offerings while ensuring seamless and dependable event delivery. Users often seek alternatives to HookMesh due to a variety of reasons including pricing concerns, specific feature requirements, or compatibility with existing platforms. When considering alternatives, it's essential to evaluate aspects such as reliability, ease of use, customer support, and integration capabilities to ensure that the chosen solution meets their unique needs. Selecting the right webhook delivery service is crucial for maintaining a smooth operational flow in any SaaS product. Users should prioritize features like automatic retries, transparency in delivery tracking, and the ability to manage webhook endpoints efficiently. A robust customer support system and a user-friendly interface are also vital factors that can greatly enhance the overall experience when managing webhooks.
LLMWise Alternatives
LLMWise is a unified API platform in the AI assistants category, designed to give developers a single access point to multiple large language models like GPT, Claude, and Gemini. It uses intelligent auto-routing to select the best model for each specific prompt, aiming to maximize performance and simplify integration. Users often explore alternatives for various reasons, including specific pricing structures, the need for different feature sets like advanced analytics or custom model support, or platform requirements such as on-premise deployment. Some may seek a different balance between control, cost, and convenience. When evaluating other solutions, key considerations include the range of supported AI models, the sophistication of routing and failover logic, transparent and flexible pricing without mandatory subscriptions, and robust tools for testing and optimizing performance across different providers.