Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
Agenta centralizes LLM development, enabling teams to build reliable AI apps with streamlined collaboration and.
Last updated: March 1, 2026
OpenMark AI benchmarks over 100 LLMs for your specific tasks, providing quick insights on cost, speed, quality, and stability without any setup.
Last updated: March 26, 2026
Visual Comparison
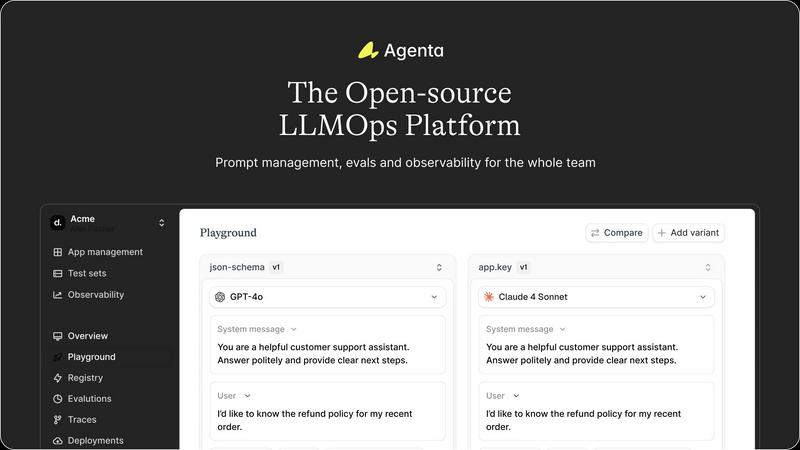
Agenta
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta centralizes all your prompts, evaluations, and traces in one platform, eliminating the chaos of scattered documents and workflows. This unified approach not only enhances visibility but also improves collaboration among team members.
Automated Evaluations
With Agenta, you can create a systematic process to run experiments, track results, and validate every change through automated evaluations. This minimizes guesswork and allows teams to make data-driven decisions in real-time.
Comprehensive Observability
Agenta offers robust observability tools that trace every request and help identify failure points in AI systems. Annotating these traces with team feedback enables quick debugging, turning potential issues into valuable learning opportunities.
Collaborative Workflow
Agenta fosters collaboration among product managers, domain experts, and developers by providing a user-friendly interface for editing, experimenting, and evaluating prompts. This integration means everyone can contribute to the development process without needing extensive technical knowledge.
OpenMark AI
Intuitive Task Configuration
OpenMark AI offers a user-friendly interface where users can easily describe the tasks they want to benchmark. This intuitive task configuration allows for both simple and advanced setups, enabling users to tailor their benchmarking experience according to their specific requirements.
Real-Time Benchmarking
The platform conducts real-time benchmarking by executing actual API calls to various models instead of relying on cached marketing data. This feature ensures that users receive accurate and timely insights into model performance, allowing for meaningful comparisons based on real usage scenarios.
Comprehensive Model Catalog
OpenMark AI supports a vast catalog of over 100 AI models, covering a wide range of tasks such as classification, translation, data extraction, and more. This extensive selection enables users to find the most effective model for their particular needs, ensuring optimal performance for diverse applications.
Cost and Quality Analysis
With OpenMark AI, users can analyze the cost efficiency of each model by comparing the quality of outputs relative to their API costs. This feature is crucial for teams that prioritize both budget considerations and the effectiveness of their AI solutions, ensuring they get the best value for their investment.
Use Cases
Agenta
Team Collaboration for LLM Development
Agenta is ideal for teams working on LLM applications, fostering collaboration between developers and subject matter experts. Its centralized platform ensures that everyone is aligned, reducing the chances of miscommunication.
Efficient Prompt Iteration
With a unified playground for prompt comparison, teams can iterate on prompts collectively. This feature allows for real-time feedback and adjustments, ensuring that the best versions are always in play.
Evidence-Based Experimentation
Agenta allows teams to replace guesswork with evidence in their LLM development processes. Automated evaluations provide systematic tracking of experiments, enabling teams to validate changes efficiently.
Debugging and Performance Monitoring
Agenta empowers teams to monitor AI systems in real time, providing insights into performance and potential regressions. This capability is essential for maintaining the reliability of LLM applications and improving user satisfaction.
OpenMark AI
Model Selection for AI Features
OpenMark AI is ideal for teams looking to select the best AI model for new features. By benchmarking various models against specific tasks, teams can confidently choose the right model that meets their needs for quality and performance.
Pre-Deployment Validation
Before deploying AI features, developers can use OpenMark AI to validate their model choices. This ensures that the selected models not only perform well in theory but also deliver consistent results in practice, minimizing the risk of post-deployment issues.
Cost Management for AI Projects
For organizations with budget constraints, OpenMark AI provides insights into the actual costs associated with using different models. Teams can make informed decisions based on the cost-effectiveness of models, allowing them to manage expenditures on AI services efficiently.
Research and Development
Research teams can leverage OpenMark AI for exploratory analysis of various AI models. By benchmarking models against complex tasks, they can identify emerging trends and capabilities, ultimately contributing to innovative AI solutions and advancements.
Overview
About Agenta
Agenta is an innovative open-source LLMOps platform specifically crafted to streamline the development of reliable Large Language Model (LLM) applications. Designed as a collaborative hub, it allows AI teams—including developers and subject matter experts—to work together effectively throughout the entire LLM lifecycle. One of Agenta's primary challenges is addressing the unpredictability inherent in LLMs, which can lead to fragmented workflows and communication silos. By centralizing prompt management, evaluation processes, and observability, Agenta significantly enhances team collaboration, automates evaluations, and improves debugging capabilities. This enables teams to iterate rapidly while ensuring their LLM applications are robust and dependable. Whether you are a developer focused on model optimization or a product manager working to enhance user experience, Agenta empowers you to harness the full potential of LLMs through a structured, evidence-based approach.
About OpenMark AI
OpenMark AI is a powerful web application designed specifically for task-level benchmarking of large language models (LLMs). It empowers developers and product teams to effectively evaluate and compare multiple AI models before integrating them into their applications. With OpenMark AI, users can articulate their testing needs in plain language, facilitating an intuitive setup process. The platform allows simultaneous testing against a wide array of models, providing comprehensive comparisons on key performance metrics such as cost per request, latency, scored quality, and stability across repeated runs. This emphasis on variance ensures that users are not misled by a single favorable output. By eliminating the need for separate API keys for OpenAI, Anthropic, or Google, OpenMark AI streamlines the benchmarking process. It is particularly valuable for organizations focused on pre-deployment decisions, ensuring that they select the most suitable model for their specific workflow at the best possible cost.
Frequently Asked Questions
Agenta FAQ
What kind of teams can benefit from Agenta?
Agenta is tailored for AI development teams, including developers, product managers, and domain experts who are involved in building LLM applications. Its collaborative features enhance workflow across diverse roles.
How does Agenta enhance prompt management?
Agenta centralizes prompt management by storing all prompts, evaluations, and traces within a single platform. This reduces the confusion that comes with scattered documents and allows for easier collaboration among team members.
Can Agenta integrate with existing tools?
Yes, Agenta seamlessly integrates with popular frameworks and models, including LangChain, LlamaIndex, and OpenAI. This flexibility allows teams to build on their existing tech stack without vendor lock-in.
Is Agenta suitable for production environments?
Absolutely. Agenta is designed for production environments, offering tools for monitoring performance, debugging issues, and gathering user feedback, ensuring that your LLM applications remain reliable and effective.
OpenMark AI FAQ
How does OpenMark AI handle API integrations?
OpenMark AI simplifies the process by eliminating the need for users to configure separate API keys for different models. The platform handles all API integrations seamlessly, allowing users to focus on benchmarking without technical hurdles.
What types of tasks can I benchmark with OpenMark AI?
OpenMark AI supports a diverse range of tasks, including classification, translation, data extraction, agent routing, and more. This versatility allows users to benchmark models across various applications tailored to their specific needs.
Are there limitations on the number of benchmarks I can run?
While OpenMark AI provides both free and paid plans, the specific limits on benchmarks may vary based on the chosen plan. Users can check the in-app billing section for detailed information regarding their plan's limitations and benefits.
How can I ensure consistent results across model tests?
OpenMark AI is designed to provide stability in results by conducting multiple runs of the same task. This feature allows users to observe any variance in model performance, helping them make informed decisions based on consistent output quality.
Alternatives
Agenta Alternatives
Agenta is an essential open-source platform that centralizes the development of Large Language Model (LLM) applications, making it a pivotal tool for AI teams. It streamlines workflows, enhances collaboration, and automates evaluations throughout the LLM lifecycle, catering to developers and product managers alike. As users delve deeper into their LLM projects, they often seek alternatives due to varying needs such as pricing, specific feature sets, or compatibility with existing platforms. When looking for an alternative to Agenta, it's crucial to assess several key factors. Consider the specific functionalities that align with your team's requirements, the overall user experience, and the level of support available. Additionally, evaluate the integration capabilities with your current tools and whether the platform fosters collaboration effectively. A suitable alternative should not only meet your technical needs but also enhance your development processes.
OpenMark AI Alternatives
OpenMark AI is a cutting-edge web application designed for benchmarking various large language models (LLMs) on a task-by-task basis. It falls within the category of development tools, specifically targeting developers and product teams who require precise metrics to evaluate model performance. Users often seek alternatives to OpenMark AI for reasons such as varying pricing structures, different feature sets, or specific platform compatibility that better aligns with their unique project requirements. When considering alternatives, it’s crucial to assess factors such as the range of models supported, the granularity of benchmarking metrics, and the ease of use in terms of setup and execution. Additionally, understanding the cost efficiency in relation to quality and stability of outputs across multiple runs is essential in making an informed decision. A well-rounded alternative should cater to the specific needs of your team while providing reliable and actionable insights.