Agent to Agent Testing Platform vs LLMWise
Side-by-side comparison to help you choose the right tool.
Agent to Agent Testing Platform
Validate AI agent behavior across chat, voice, and multimodal systems to ensure compliance and mitigate risks.
Last updated: February 28, 2026
LLMWise
Access all top AI models through one API with smart routing and pay only for what you use.
Last updated: February 28, 2026
Visual Comparison
Agent to Agent Testing Platform
LLMWise
Feature Comparison
Agent to Agent Testing Platform
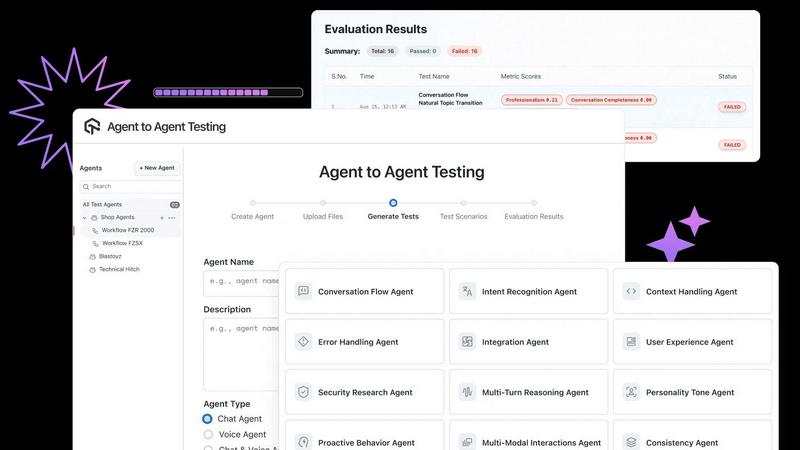
Automated Scenario Generation
This feature automates the creation of diverse test scenarios for AI agents, enabling the simulation of various interactions across chat, voice, and phone channels. This ensures comprehensive testing to identify potential weaknesses.
True Multi-Modal Understanding
The platform supports testing beyond mere text inputs. Users can define requirements or upload documents containing images, audio, and video, enabling the evaluation of AI agents in real-world situations with multifaceted input types.
Autonomous Test Scenario Generation
Access a library of hundreds of pre-defined test scenarios or create custom scenarios tailored to specific needs. This feature allows users to assess how AI agents perform under various conditions, ensuring a thorough evaluation.
Diverse Persona Testing
Utilize a range of personas representing different end-user behaviors and needs during testing. By simulating interactions with personas such as International Caller or Digital Novice, the platform ensures that AI agents perform effectively for diverse user types.
LLMWise
Intelligent Model Routing
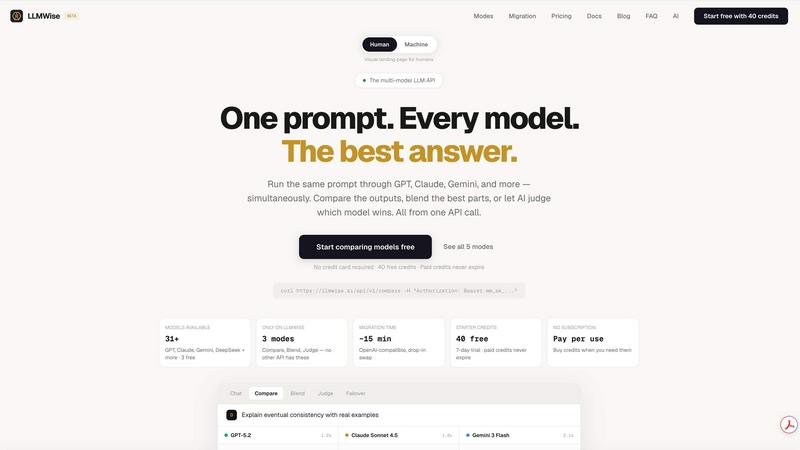
This is the foundational, must-have feature. You send a single prompt to the LLMWise API, and its smart routing engine automatically selects the optimal large language model for that specific task. It intelligently matches prompts to model strengths, sending coding queries to GPT, creative briefs to Claude, and translation requests to Gemini. This eliminates the guesswork and manual model selection, ensuring you consistently get the highest quality output for every request without any extra effort.
Compare, Blend, and Judge Modes
LLMWise provides essential orchestration modes that are critical for production-grade AI applications. Compare mode runs a single prompt across multiple models side-by-side in one request, allowing you to instantly benchmark speed, cost, and output quality. Blend mode takes this further by synthesizing the best parts of each model's response into one superior, consolidated answer. Judge mode enables models to evaluate and critique each other's outputs, providing an automated layer of quality assurance and validation.
Resilient Circuit-Breaker Failover
This feature is non-negotiable for any serious application. LLMWise includes a built-in circuit-breaker system that provides automatic failover to backup models if a primary provider experiences downtime or high latency. This ensures your application remains operational and resilient, never breaking due to external API outages. It is a critical component for maintaining uptime and delivering a reliable experience to your end-users without manual intervention.
Test, Benchmark, and Optimize Suite
You must have the tools to optimize performance and cost. LLMWise offers a comprehensive suite for testing and optimization, including benchmark suites, batch testing capabilities, and configurable optimization policies. You can set policies to prioritize speed, cost, or reliability for different types of requests. Automated regression checks ensure new model versions or prompts do not degrade your application's output quality, making it an indispensable tool for continuous improvement.
Use Cases
Agent to Agent Testing Platform
Quality Assurance for AI Products
Enterprises can leverage the platform to conduct rigorous quality assurance testing of their AI products, ensuring they meet performance standards before launching to the public.
Performance Evaluation of AI Agents
Organizations can evaluate the accuracy, empathy, and professionalism of their AI agents through detailed analysis and feedback, leading to improved user interactions and satisfaction.
Compliance and Risk Assessment
The platform helps businesses assess compliance with regulatory standards and internal policies by identifying potential risks and areas of concern in AI behavior, thus enhancing governance.
Continuous Improvement and Optimization
Through regression testing and risk scoring, companies can continuously refine their AI agents, prioritizing critical issues and optimizing overall performance for better user engagement.
LLMWise
Development and Prototyping
Developers can rapidly prototype and build AI features using the 30 permanently free models available at zero cost. This allows teams to test ideas, validate prompts, and ship initial versions of their application without any financial commitment. The compare mode is essential for debugging and determining which model handles specific edge cases or instructions most effectively during the development phase.
Production Application Orchestration
For applications in production, LLMWise is a necessity for managing AI workloads reliably and cost-effectively. The smart routing ensures every user query is handled by the best-suited model, while the failover system guarantees uptime. Companies can implement optimization policies to balance response speed and cost across millions of requests, ensuring a scalable and efficient AI backend through a single, simple API integration.
AI Output Quality Enhancement
Teams that require the highest possible quality output must use the Blend and Judge modes. This is critical for generating marketing copy, legal document analysis, complex research summaries, or competitive intelligence reports. By leveraging multiple top-tier models and synthesizing their strengths, you can produce results that surpass the capability of any single provider, turning AI from a tool into a competitive advantage.
Cost Optimization and Vendor Management
LLMWise is essential for finance-conscious teams tired of subscription sprawl. The platform allows you to bring your own API keys (BYOK) and pay provider prices directly, eliminating markups. Alternatively, you can use a unified credit system. This approach, combined with the ability to compare model costs per request and utilize free models for fallback, provides unprecedented visibility and control over AI expenditure, making it a mandatory financial management tool.
Overview
About Agent to Agent Testing Platform
Agent to Agent Testing Platform is a pioneering AI-native quality assurance framework specifically designed for validating the behavior of AI agents in real-world scenarios. As AI systems become increasingly autonomous and complex, traditional quality assurance practices fall short in addressing the dynamic nature of these agents. This platform offers a comprehensive testing solution for various AI-driven interactions, including chatbots, voice assistants, and phone caller agents. By evaluating AI agents through full, multi-turn conversations, the platform helps enterprises ensure their AI systems are robust, reliable, and ready for production. The platform is particularly valuable for businesses that rely on AI technologies, as it uncovers potential failures, biases, and other critical metrics that can impact user experiences.
About LLMWise
LLMWise is the essential, unified API platform for developers and businesses that demand the best AI performance for every task without the operational nightmare. It solves the critical problem of AI provider fragmentation by giving you a single, powerful endpoint to access over 62 models from 20+ leading providers, including OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek. The core value proposition is absolute necessity: stop juggling multiple subscriptions, managing separate API keys, and guessing which model to use. LLMWise introduces intelligent orchestration, where smart routing automatically matches each prompt to the optimal model based on its specialty—code to GPT, creative writing to Claude, translation to Gemini. Beyond simple access, it provides must-have tools for comparison, blending outputs for superior quality, and ensuring resilience with automatic failover. Built for developers who prioritize performance, cost-efficiency, and reliability, LLMWise eliminates complexity and locks you into a pay-as-you-go model with no subscriptions, ensuring you only pay for what you use while maintaining complete control.
Frequently Asked Questions
Agent to Agent Testing Platform FAQ
What types of AI agents can be tested using this platform?
The platform is designed to test various AI agents, including chatbots, voice assistants, and phone caller agents, across multiple interaction scenarios.
How does the platform ensure comprehensive testing?
The Agent to Agent Testing Platform automates scenario generation, allowing for diverse testing across chat, voice, and phone interactions, ensuring thorough coverage of potential use cases.
Can I create custom test scenarios?
Yes, users can access a library of pre-defined scenarios or create custom scenarios tailored to their specific requirements, providing flexibility in testing.
What metrics can be evaluated using this platform?
The platform evaluates key metrics such as bias, toxicity, hallucinations, effectiveness, accuracy, empathy, and professionalism, ensuring a holistic view of AI agent performance.
LLMWise FAQ
How does the pricing work?
LLMWise operates on a transparent, pay-as-you-go credit system with no monthly subscriptions. You start with 20 free trial credits that never expire. After that, you only pay for what you use. Crucially, you have two options: you can use LLMWise credits, or you can Bring Your Own Keys (BYOK) from providers like OpenAI and Anthropic and pay their standard rates directly through LLMWise's dashboard. Over 30 models are also available at a permanent cost of 0 credits for testing and fallback.
What are the free models?
LLMWise provides access to over 30 models that cost 0 credits to use, permanently. This includes models from Google (Gemma 3 series), Meta (Llama series), Arcee AI, Mistral, and others. These are essential for prototyping, serving as a cost-free fallback path during traffic spikes, and for benchmarking against paid models to make informed routing decisions. The availability of these free models is automatically synced from the providers' own catalogs.
How does the smart routing work?
The smart routing feature automatically analyzes your prompt and directs it to the model best suited for the task. This routing is based on proven model specialties—for instance, code generation and complex reasoning are routed to models like GPT-4o or GPT-5.2, while creative writing and nuanced dialogue are sent to Claude Sonnet or Opus. This ensures you consistently get optimal performance without needing to be an expert on every model's specific capabilities.
Is there a risk of vendor lock-in?
No, avoiding vendor lock-in is a core principle of LLMWise. By using the platform, you are actually future-proofing your application against lock-in to any single AI provider. Your integration is with the LLMWise API. If a new, superior model is released from any provider, you can immediately access it through the same endpoint. Furthermore, the BYOK option means you maintain direct relationships with providers, and you can easily compare all alternatives side-by-side.
Alternatives
Agent to Agent Testing Platform Alternatives
The Agent to Agent Testing Platform is an innovative AI-native quality assurance framework that specializes in validating agent behavior across various communication channels, including chat, voice, phone, and multimodal systems. This platform stands out in the realm of AI assistants, addressing the unique challenges posed by increasingly autonomous AI systems that require more than traditional testing methods. Users often seek alternatives due to factors such as pricing, specific features that meet unique business needs, or the desire for a more tailored platform that aligns with their operational requirements. When exploring alternatives, it’s crucial to assess the platform's capability to handle multi-turn conversations effectively, the depth of its testing framework, and its ability to uncover edge cases and long-tail failures. Additionally, consider the scalability of the solution, its compliance with security standards, and the level of support provided to ensure successful implementation and continuous improvement.
LLMWise Alternatives
LLMWise is a unified API platform in the AI assistants category, designed to give developers a single access point to multiple large language models like GPT, Claude, and Gemini. It uses intelligent auto-routing to select the best model for each specific prompt, aiming to maximize performance and simplify integration. Users often explore alternatives for various reasons, including specific pricing structures, the need for different feature sets like advanced analytics or custom model support, or platform requirements such as on-premise deployment. Some may seek a different balance between control, cost, and convenience. When evaluating other solutions, key considerations include the range of supported AI models, the sophistication of routing and failover logic, transparent and flexible pricing without mandatory subscriptions, and robust tools for testing and optimizing performance across different providers.